
US Election 2024 - FiveThirtyEight review
US Election 2024 - FiveThirtyEight review

In May of 2023, ABC News and Disney had a problem. They had just decided to sack Nate Silver and much of his data journalism at FiveThirtyEight as one small part of a wider 7,000 job layoff. But Silver held the IP to his election model.
So while ABC/Disney had the FiveThirtyEight brand, and as many of the team there as they wanted to continue paying (not that many, it turned out), they did not have the central crown jewel - the election model that had brought Silver to prominence in 2008, worked similarly well in 2012, had done less disastrously than most in 2016, and had done another solid job against growing competition in 2020.

So ABC/Disney brought in a much younger model (in several senses), in the shape of G. Elliot Morris, who had previously built The Economist’s election model, and in 2020 had engaged in entertaining-but-not-terribly-enlightening twitter feuds with Silver on methodology and certainty. Morris completely replaced FiveThirtyEight’s model with a new one - with some continuity to the one he had built for The Economist, but also with additional help of the head honcho of applied Bayesian methodology: Andrew Gelman of Columbia University.
So FiveThirtyEight’s model is now Morris’ model - and we do know the rough outlines of the methodology; an almost entirely Bayesian set-up, borrowing a great deal from the Dynamic Linear modelling approach pioneered by Drew Linzer.
Nate Silver is now with his own (two person) outfit at The Silver Bulletin, with pretty much exactly his old FiveThirtyEight model which uses averages and blending - broadly, it’s frequentist … and the feuds are back (Morris adjusted the FiveThirtyEight model after the most recent scrap).
It’s happening again
Given this history (and this beef), let’s look at how FiveThirtyEight and The Silver Bulletin’s reads changed in the days after Kamala Harris and Donald Trump’s first (and probably only) debate. This was a debate which Harris was widely seen to have won, and which many expected to have some effect on the polls.
Ignore the levels for a moment (i.e., the absolute numbers), we are interested in the dynamics (i.e., how those numbers change).
Here we go again. FiveThirtyEight (Morris’ model) recognised a 5ppt probability jump almost immediately - on the 13th September, while Silver’s took another four days drifting doing pretty much nothing, before finally recognising a jump only on the 17th September. Silver’s model seems to take longer to move.
Frequentism and Bayesianism fight once more
Why is this happening (again)?
At a top-line - I think it’s the Bayesian thing again.
Neither model are open-source, but both do lay out top-line overviews of their methodology, so we know enough to understand some fairly profound philosophical differences between them.
Silver’s model is fairly traditional. It takes state polls (plus substitutes where there’s not much polling), adjusts them for various factors by blending averages with weights,1 and then uses these adjusted vote shares to give probability for each candidate to win that state. Then, he looks at how correlated the states are in moving together (especially if there is error in the polling) and simulates thousands of scenarios, deriving national probabilities from the overall picture.
FiveThirtyEight’s model is fully Bayesian. That is, while it takes polling, fundamentals and other adjustments into account in the same way that Silver’s does, it blends them together by encoding them as “beliefs” about the a candidate’s true level of support, and updating with a “prior belief” + “new evidence” = “posterior belief” approach, where the new evidence is incorporated using Bayes’ theorem. Then, they simulate from this final model in much the same way that Silver does.
So what does this have to do with whose forecast changes first?
Let’s take a single example. Over the weekend after the debate, a Selzer state poll was released. Harry Enten (yet another polling expert) described it as “arguably Harris’ best poll of the campaign” and wrote up in a detailed article for CNN.
However, this description - and his reaction in general - might look slightly odd. First, this poll showed Trump winning - and winning clearly, by 5 percentage points. And second, it was for Iowa. Which is not very relevant to most scenarios we are talking about in a near coin-flip race. Here it is on FiveThirtyEight’s “snake” of likeliest state results.
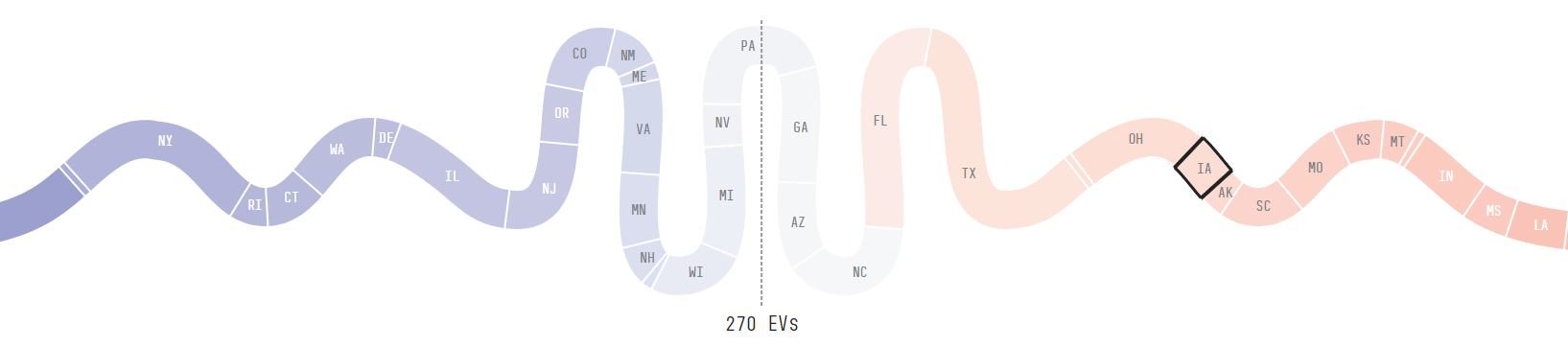
That is, Harris would likely have won Florida and Texas before Iowa became relevant. The media would be too busy trying to come up with superlatives to describe her landslide victory to worry about what had happened in Iowa.
So, why should a poll in this state be significant?
Trump is polling +5 in Iowa. In any frequentist approach, this is interesting, but pretty much irrelevant. Trump was expected to win by a lot more than that, but he’s still overwhelmingly likely to win. All this now means is that whereas before, Harris had a tiny probability of winning there and the state was pretty much irrelevant, now it’s slightly less tiny chance, and the state is still irrelevant. Nothing moves much.
But in Bayesian terms, this is an earthquake. The point being that previous Iowa polls had Trump winning by margins in the double figures. The previous Selzer poll had him on +18ppts. And so in a Bayesian framework, this means you should update your beliefs with a huge update on how Harris is viewed by Iowa voters and people relevantly like them, in other states. The Bayesian framework gives the tools on how you should do this, and how these belief updates should ripple through to update beliefs on other states, and then onto on the national level. The whole model will move.
This of course is only one poll, but this update was repeated by a flood of (fairly low quality) national polling, and several other state polls in apparently unrelated places like Wisconsin. All of which flowed their way through the Bayesian framework and updated beliefs about the whole race, early on and from fairly limited data. The Bayesian model concluded that the race had changed, and did so only a few days after the debate.
In contrast, Silver and other more traditional frequentist approaches incorporated the same information, but with very small effects. To get proper moves, they needed to wait for new state polling in the swing states (PA, GA, NV, MI, WI), and for better quality national polls to blend into their averages, before their models slowly updated each part any new reality.
Roughly, FiveThirtyEight has a set-up where a “shock” poll anywhere will transmit new information and update the whole model. This requires confidence that your overall system is right - that things move together in the same way as they have in the past. In contrast, Silver needs to wait for new reads from some key parts of the system for his headline numbers to update: good quality polling in the swing states in particular. And this only comes with time. The trade-off here is that you are less reliant on your model being fully correct - it looks for direct impact on the critical parts of the system.
This gives some insight into what the so-called “Nerd wars” were about in 2020. Silver was indignant that Morris’ approach was updating to early information, and projecting confidence. This required a belief that his overall setup was right - i.e., that the current election would reflect the dynamics of previous elections. Silver was worried that factors like COVID had uprooted this, and that Morris’ confidence in projecting new information across his Bayesian framework may have been based entirely on a mistaken model of the dynamics.
In fact, in this case, it was pretty much a draw. Both models did fine by the time polling day arrived - but Morris’ model got there earlier.
And I think this is what we’ll have this time too. The FiveThirtyEight model (appears to be) a fully Bayesian approach, which will react to the entirety of the data coming in - even if it is from polls in apparently irrelevant states, which are going to have no practical direct effect on the outcome. It will react to news earlier and more often.
In another way though, the FiveThirtyEight model is much more conservative. It is keeping a much more open mind on the “tail” possibilities, than are other models. This read is from a week ago, but serves to show what is going on - it is a read of the probabilities assigned to “tail” possibilities: a landslide victory in either direction.
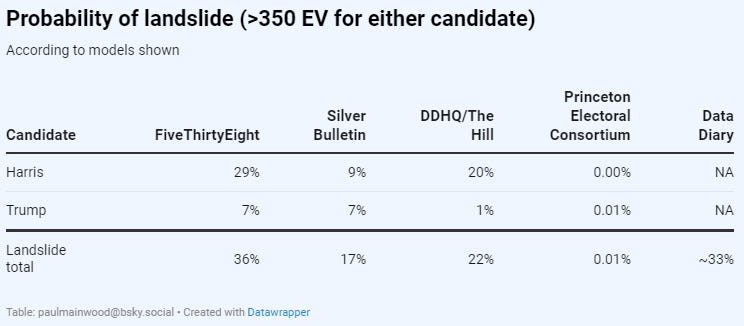
That is, FiveThirtyEight may react fast to new news, but it has a lot of openness that yet more news might come in to further reshape the race - and in particular that things may change to the point that one candidate or another might see a large victory - something that current polling is definitely not pointing towards. Silver is much more sure that the current race he is projecting, will continue to polling day.
Again, I’m afraid I side with Morris’ approach here. There is plenty of time for the race to change, and in either direction. Given the volatility of historical and current races, a great deal more allowance should be given for race-moving events.
Bayesians unite
So, this is a place where my clear bias has to come out. I think the Bayesian framework is superior overall. It incorporates information in a principled way, rather than relying on averaging to wash out errors, and relying on rules of thumb to incorporate new information. And as such, I think the FiveThirtyEight approach is the conceptually superior one. Variations on the broad philosophy are also used in The Economist’s (new) model, and in Data Diary - an open-sourced version of the Economist’s 2020 setup.2
In addition, I think FiveThirtyEight’s handling of aspects like the convention bounce (measuring it rather than assuming it) are also superior to other approaches out there. So - for me - this model represents the state of the art in 2024.
However, there are two things that should give us pause. First, it is firmly closed-source, so we cannot, for example, understand why it is consistently giving Harris a significantly higher chance than Data Diary, which shares many of its internal features. This is probably something to do with some adjustment to polls for bias, but we cannot “see inside” to understand what is going on. This is a major minus point.
Second, there was a significant change to the FiveThirtyEight model only a month ago. They gave more weight to polls (the model was showing Biden doing OK, based almost entirely on fundamentals and incumbency advantage, and gained a lot of well-deserved criticism for doing so). They also made some technical adjustments, which seemed defensible, but it is a worrying sign to be making post-hoc rather than earlier in the process. Ideally you get your thinking straight first, and then follow it through.
As a result, we have to mark the model down on both transparency and on track record.
Overall though, my own (Bayesian) preference would be to look to FiveThirtyEight for a clear, timely and principled response to the latest information on the state of the race.
However, neither of these two picked up on the post-debate shift towards Harris as fast as FiveThirtyEight’s model did, which suggests that there are other things going on as well.
75% of that Iowa poll was conducted before the debate - deducing that 538 (using that poll) reacted quicker to the debate is incorrect.
To me, the difference you describe, between the (new) 538 and the Silver models, is not so much a difference between Bayesian and frequentist modeling as it is a difference between causal and non-causal modeling. The poll result in Iowa ripples through the 538 model because it is being modeled as an effect of the views of certain kinds of voters. Because of that, it functions as an indirect observation of those views, and because those kinds of voters live in other states too, a shift in our estimate of those voters views creates a shift in our expectations about how the vote will turn out in those other states, which in turn affects the estimates of the candidates' win probabilities. The important thing is, it's the causal assumptions in the model, not the Bayesian framework, that creates this behavior.
Now, to be fair, most causal models are Bayesian because the idea of reasoning about latent variables from their observable effects fits more naturally into a Bayesian framework than it does into a frequentist framework. The converse, however, is not true. Making a model Bayesian doesn't automatically make it causal, and a non-causal Bayesian model would perform just as badly in this instance as a non-causal frequentist model.