
I’ve been writing in a few places about using far too much mathematics to do something very simple.
I have been reminded that on this - as on so many things - I am a rank amateur.
Here’s your very simple task:
Choose a random number.
Go ahead.
Contrary to what you might think, just thinking of one is a terrible, terrible idea. Humans are awful at randomness. Magicians know this well - ask someone to pick a number between one and ten, and more people choose seven than anything else. And it gets worse. Ask them to generate a sequence of random numbers, and they go to pieces, worrying that the result “doesn’t look right” against some mental model of what randomness “should” look like.
There’s a popular classroom demonstration of this, where one student is give a coin to toss fifty times and write out the results. The other students are to write out a random sequence of heads and tails. The teacher can pick out the genuine sequence every time - it’ll be the one with the longest sequences of H or T - humans reject those as “not random enough”, despite the fact that they will appear often in any long random binary sequence.1
You need some technical help.
A few decades ago, your best bet might have been this book.

(Full text here, A million random digits with 100,000 Normal Deviates)
Published in 1955, and enjoying modest sales ever since, it’s not the most gripping page-turner of all time, but — as noted in one of its Amazon reviews— you’ll never guess the ending.
Also, and rather wonderfully, its third edition has an errata page.
The brief technical history behind the numbers in the book is worth a read — the RAND corporation’s electronic noise generator produced some unexpected effects which resulted in an odd-even discrepancy that took a great deal of work to remove. The author ends the piece by reasoning that no-one should ever need to build a true random number generator again, because pseudorandom algorithms implemented on computers should be fine. He wrote that in 1949.
In fact, pseudorandom algorithms implemented on computers are doing pretty well, but they keep on having to be updated, as people find hidden patterns within the algorithms that can be exploited.
So, people have supplemented them with randomness from atmospheric noise, various quantum probabilities, from Geiger counters and other fun approaches. Using these to generate seeds that can be fed into the pseduorandom algorithms works even better, while also proving the 1949 prediction very, very wrong. But in general, even when you do find some truly random source, you face a fundamental problem:
How can you be sure it’s working?
The problem is deep — if you have a device in front of you that is designed (or claimed to be designed) to produce random numbers, then it’s very difficult to tell truly random sequences from a perfectly functioning device from non-random numbers from a badly functioning device — say — affected by a loose connection somewhere that may have hidden patterns of its own (e.g., linked to the phasing of the power supply). Or, worse, a totally predictable sequence, inserted by a bad actor to mimic randomness, but in fact totally predictable by them.
Certainly, you can run statistical test after statistical test on the digits. These tests can rule out various types of hidden patterns in the digits (e.g., whether there is any bias, skew or kurtosis in the output). Effectively, the tests are designed to screen out any particularly egregious and obvious patterns in the results. But there is no test that can rule out all patterns. Just to give an elementary example: the decimal digits of π pass every statistical randomness test. Yet we can always predict the next digit in the sequence, and can do so with 100% certainty. Despite passing all the tests, they are as non-random as you can get.
This is not just a theoretical problem. The users of such devices tend to be banks and others who need absolutely random numbers to seed encryption devices. It would be easy for a manufacturer, or other attacker of such a random-generator device to insert non-random sequences into their generated numbers (say, every 42nd digit of π starting at the 2 millionth place), and - so long as these are statistically well-chosen to appear random - then unless you know how they are generated, they will be indistinguishable from the “true” random numbers.
What one needs is some kind of publicly scrutinisable test that guarantees randomness - that not only are the digits produced passing all the statistical tests, but that they are also not predictable in any way at all.
Here’s where the sledgehammer comes in. It’s a massive machine at the University of Colorado, based on a beautiful idea (due to Stefano Pirinio), and beautifully realised (by a team led by Stephen Bierhorst).
The basic idea goes like this.
You can detect correlations in measurements between spatially separated but entangled quantum particles, which is very odd phenomenon. However, it is always impossible to use this non-local correlation to send non-local messages. This result is called the No-Communication Theorem.
In turn, this No-Communication theorem relies on quantum outcomes being utterly, completely random. If they are not — if there is any predictable pattern in the outcomes at all — then it fails, and you can design up a scheme that allows you to send information non-locally. That is, to send a message faster than light.
This is the point where the so-called “peaceful coexistence” of quantum mechanics and special relativity happens. Quantum mechanics can maintain weird correlations over large distances, only if quantum probabilities are completely random. If they are not - if an agent can predict them - then superluminal signalling is possible.
Pironio and Bierhorst took this reasoning and turned it backwards.2
If one could show that non-local correlation exists (and we can — through Bell test experiments), then the outcomes we are measuring must be random. For if they were not, then we would be able to communicate faster than light (which, via relativity, also means being able to communicate backwards in time).
Since any entity capable of signalling backwards in time presumably has better things to do than breaking into a bank, we should conclude that these measurement outcomes are random, and so we can rely on these quantum outcomes to generate (binary) random numbers.
Sounds easy? No, it requires apparatus that took up the entire span of their L-shaped physics buildings — more than a hundred metres to a side. (It needs to be this big to make sure that there is enough time to take a measurement before light can get from A to B, and so guarantee that the correlations are non-local).
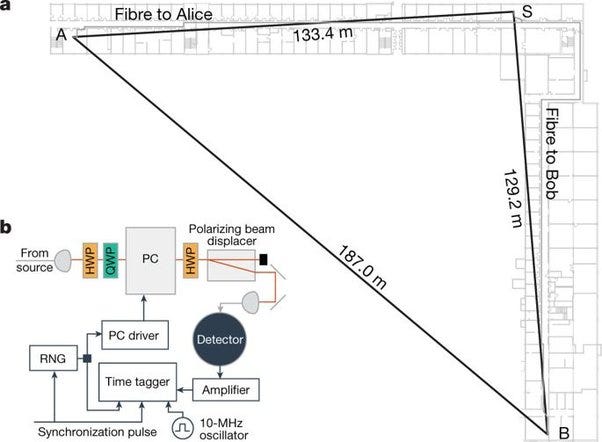
(Diagram from Bierhorst et al, Experimentally generated randomness certified by the impossibility of superluminal signals).
So, this machine can not only generate totally random digits — a claim underwritten by the laws of quantum mechanics, but can also at the same time guarantee that they are random — a claim underwritten by the theory of relativity.
Unfortunately, at present, the only machine capable of doing this is 130 metres per side, and can only produce around 100 bits per minute.
Biggest sledgehammer for the most apparently simple problem I know of. It’s a thing of beauty.
Apple had to change the algorithm for its random “shuffle” mix of songs on early iPods. Early users complained that they heard the same songs over and over, so it wasn’t really random.
Strange how many good ideas come from taking existing ideas and turning them backwards.